
무기는 끈기
[데이콘] 신용카드 사용자 연체 예측 AI 머신러닝 프로젝트 독학 기록 (2022.11.~12.) 본문
https://dacon.io/competitions/official/235713/overview/description
월간 데이콘 신용카드 사용자 연체 예측 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
Google Colaboratory
22.11.30. (수)
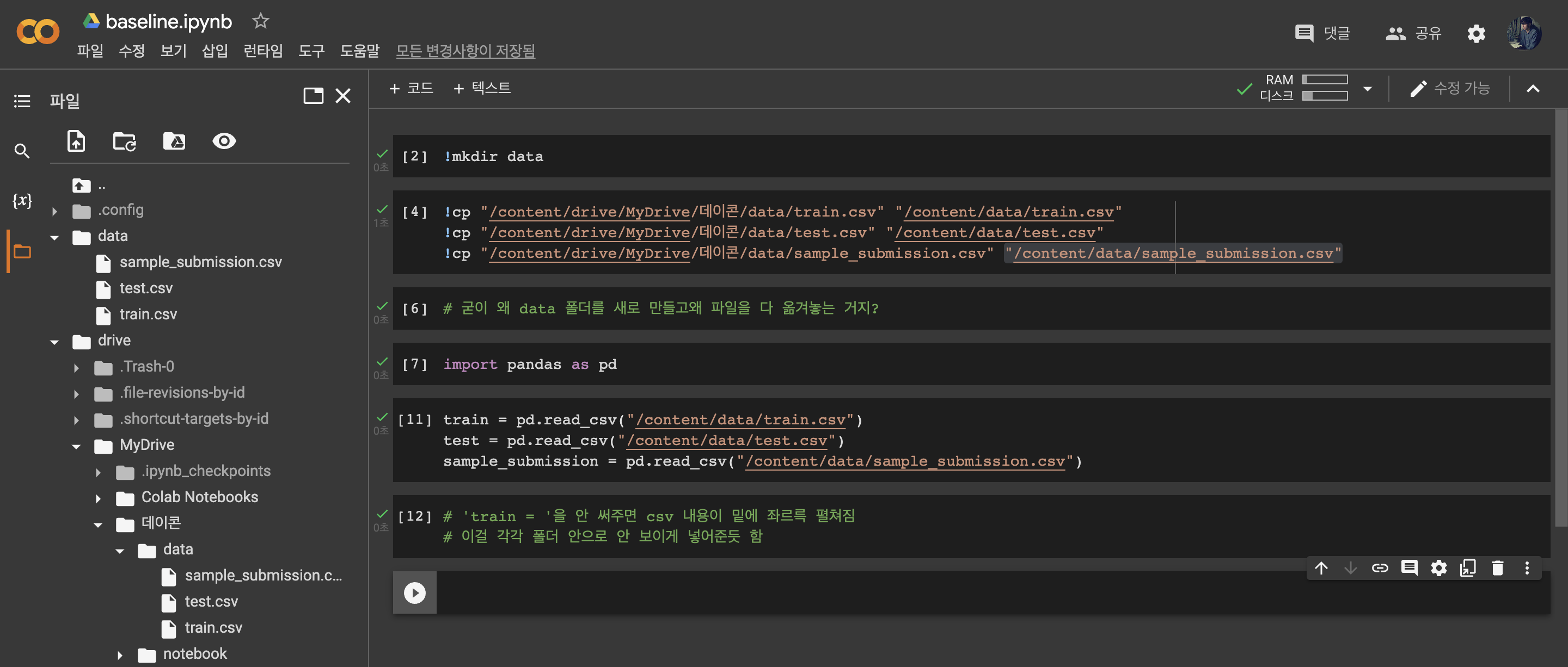
(코드 부분 확대)
내일 일찍 일어나서 마저 해야겠다.
더 하고 싶지만 오늘 이후로 내려가는 넷플 <스티브 잡스> 영화를 보기로 계획해놓았기 때문에 아쉽지만 여기서 끝~
내일은 수업 다 끝나고 나서야 뉴스 스크랩 할 수 있을 것 같다.
22.12.01.(목)
오전 6시에 기상하려고 했는데 7시 반에 기상했다..ㅜ
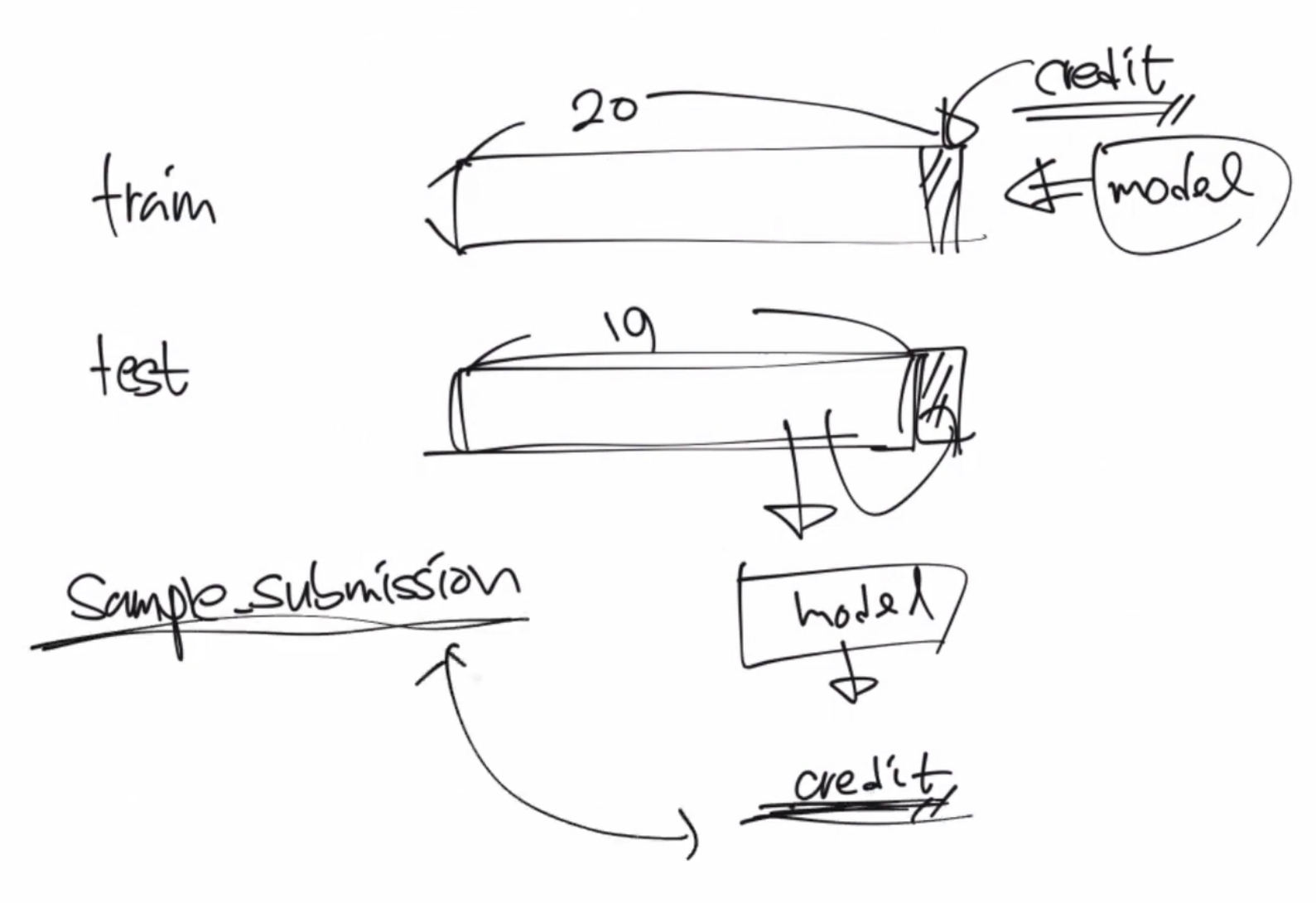
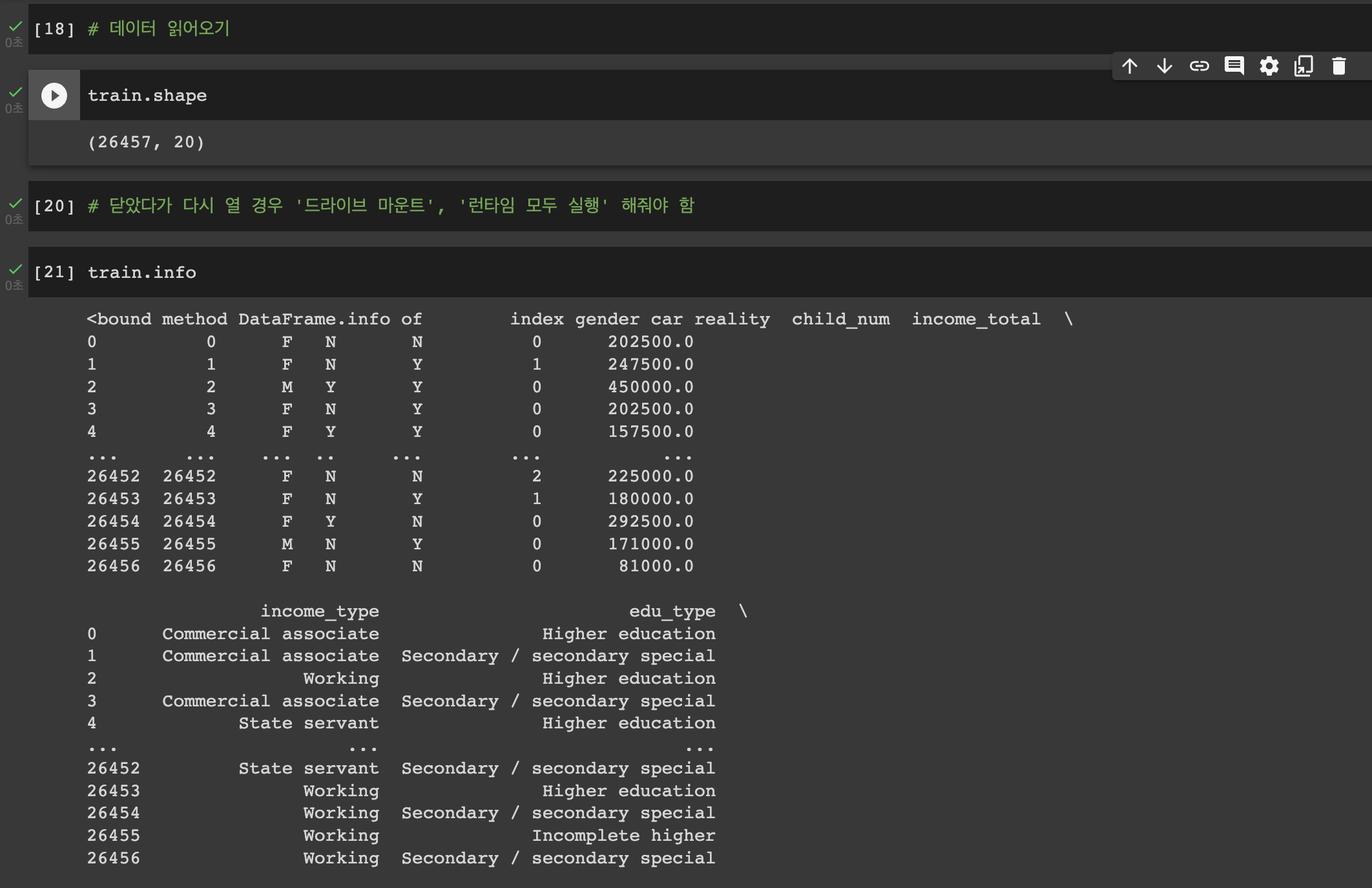
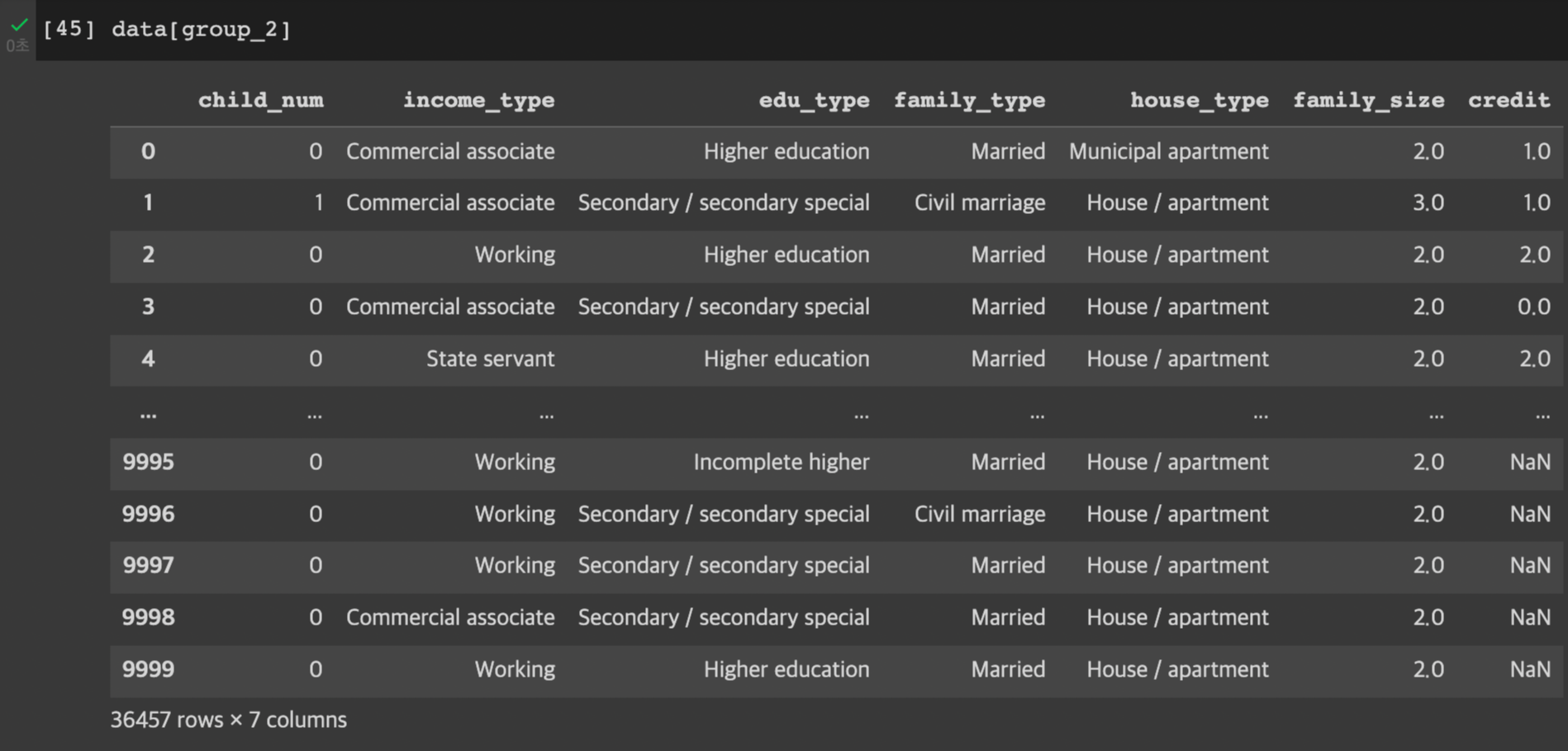
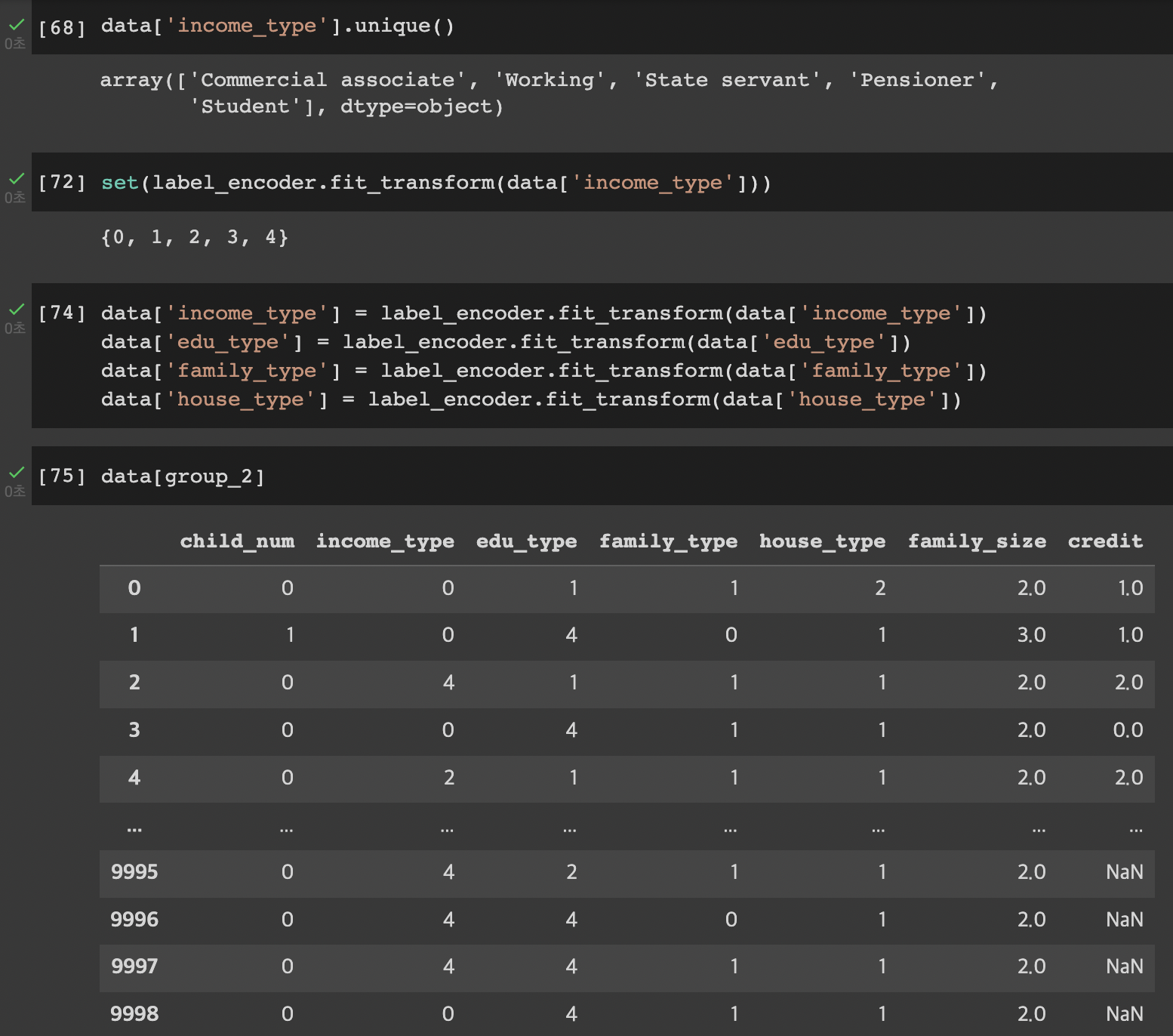
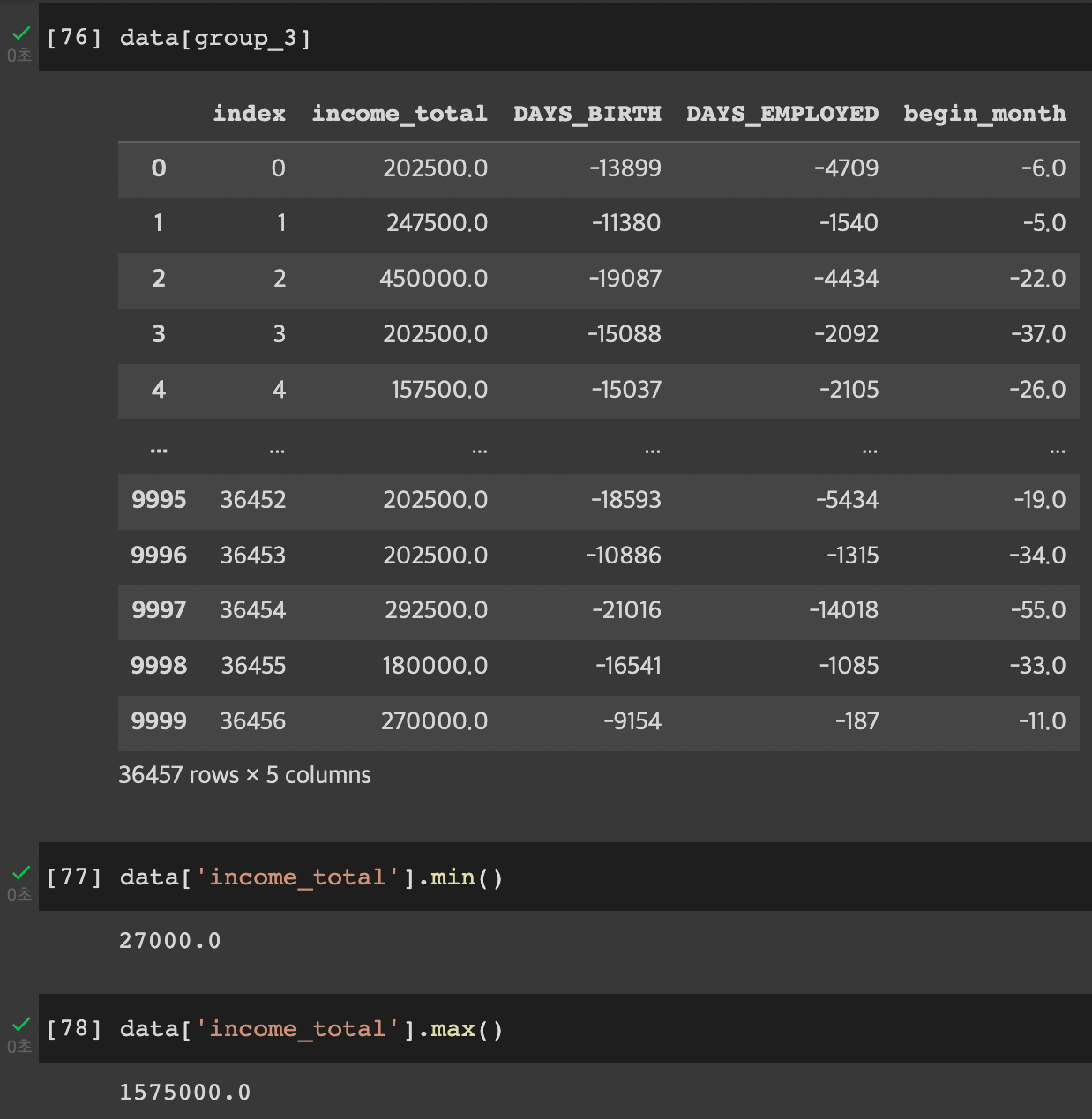
train은 컬럼이 20개고, test는 컬럼이 19개이다.
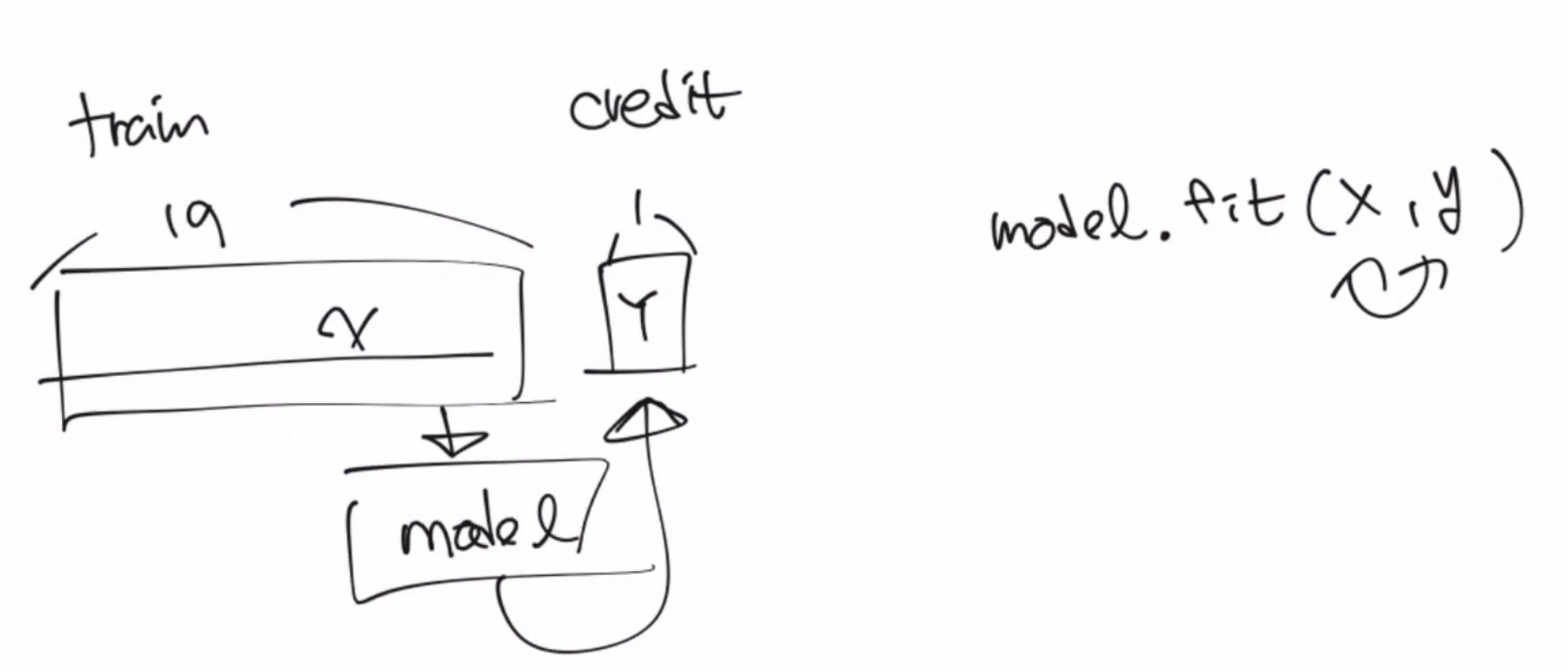
train에는 credit이라는 컬림이 하나 더 존재한다. 이것이 바로 이번 프로젝트를 통해 예측해야 하는 값이다.
train 값을 통해서 model을 학습 시킨 후, test를 model에 입력해서 credit을 예측하는 것이 프로젝트의 주요 테스크이다.
예측된 credit은 sampl+submission과 동일한 형태를 가져야 하기 때문에 이것을 참고해서 어떻게 credit을 구성하는지 예측할 수 있다.

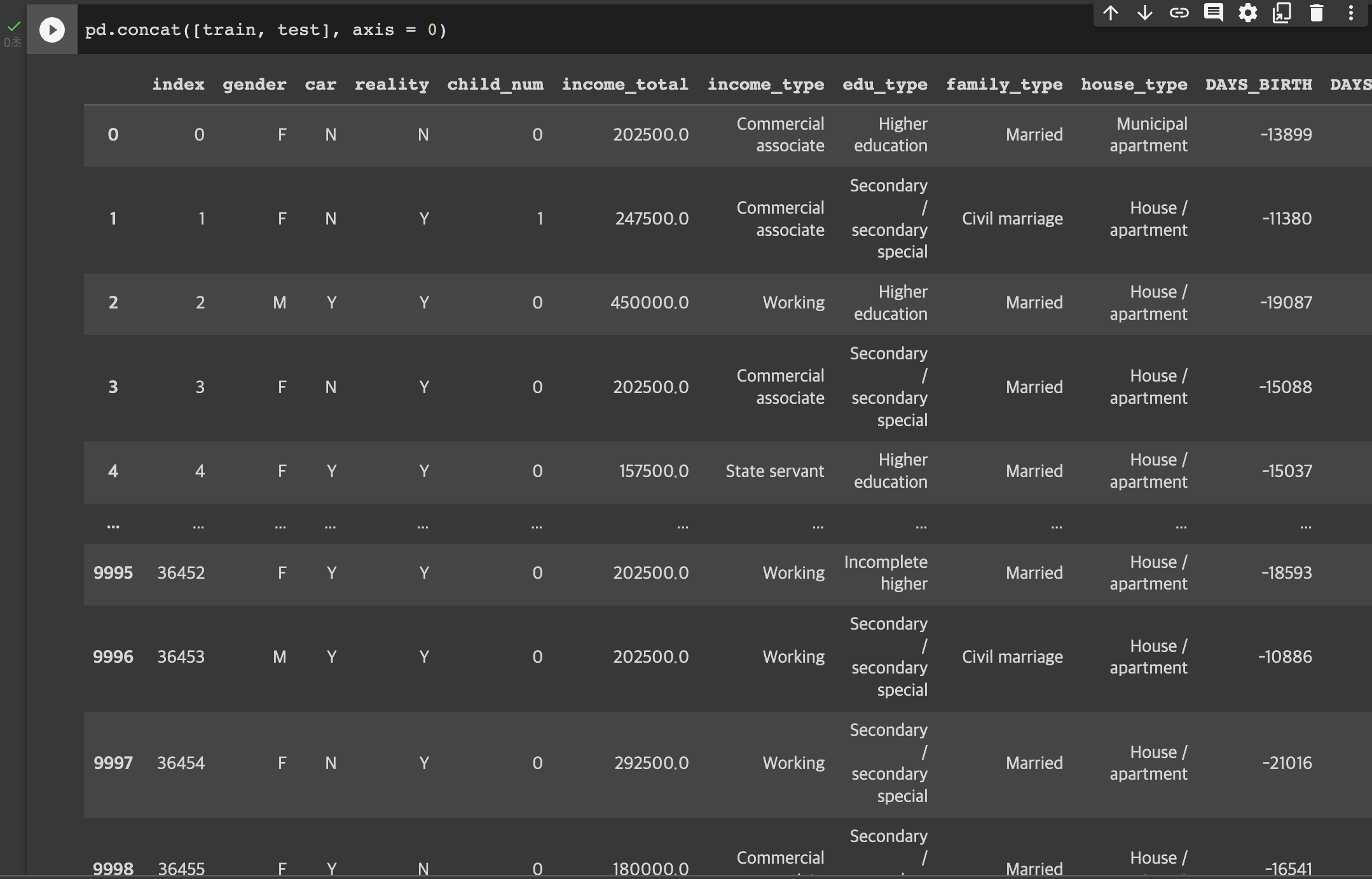
pd.concat 함수를 활용하면 train, test 데이터가 위아래로 합쳐진다.

그리고 하나 차이가 났던 credit 값은 결측치 형태로 위에 노란 표시된 것처럼 구현되어 직사각형의 데이터로 보여진다.
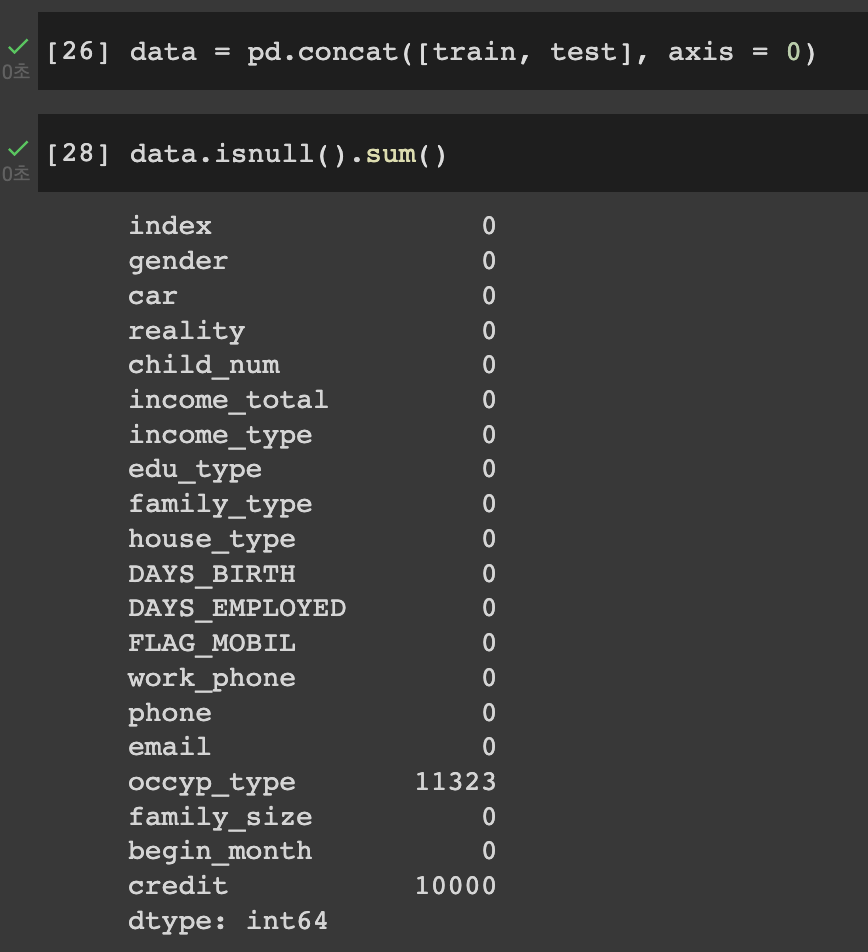
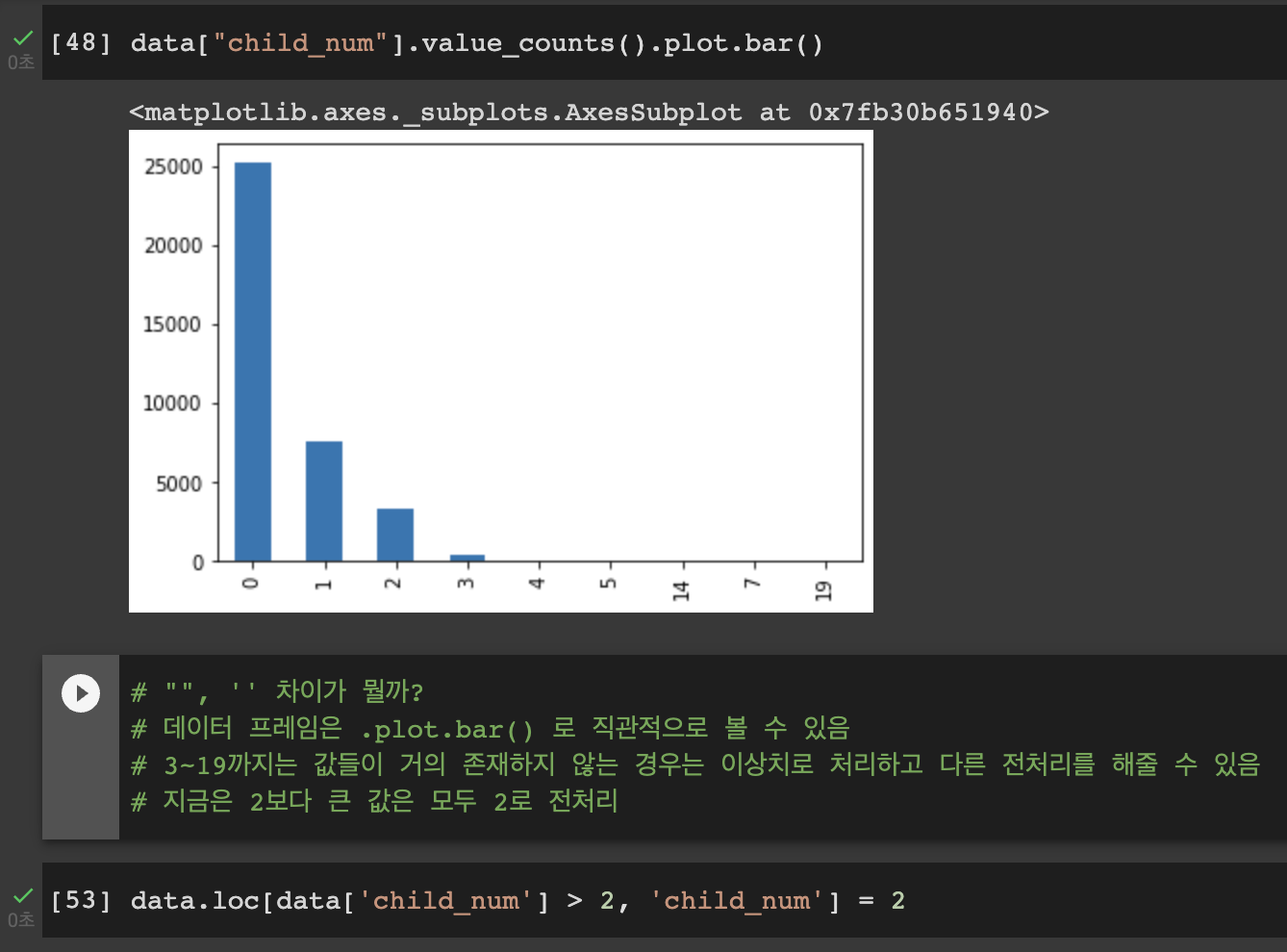
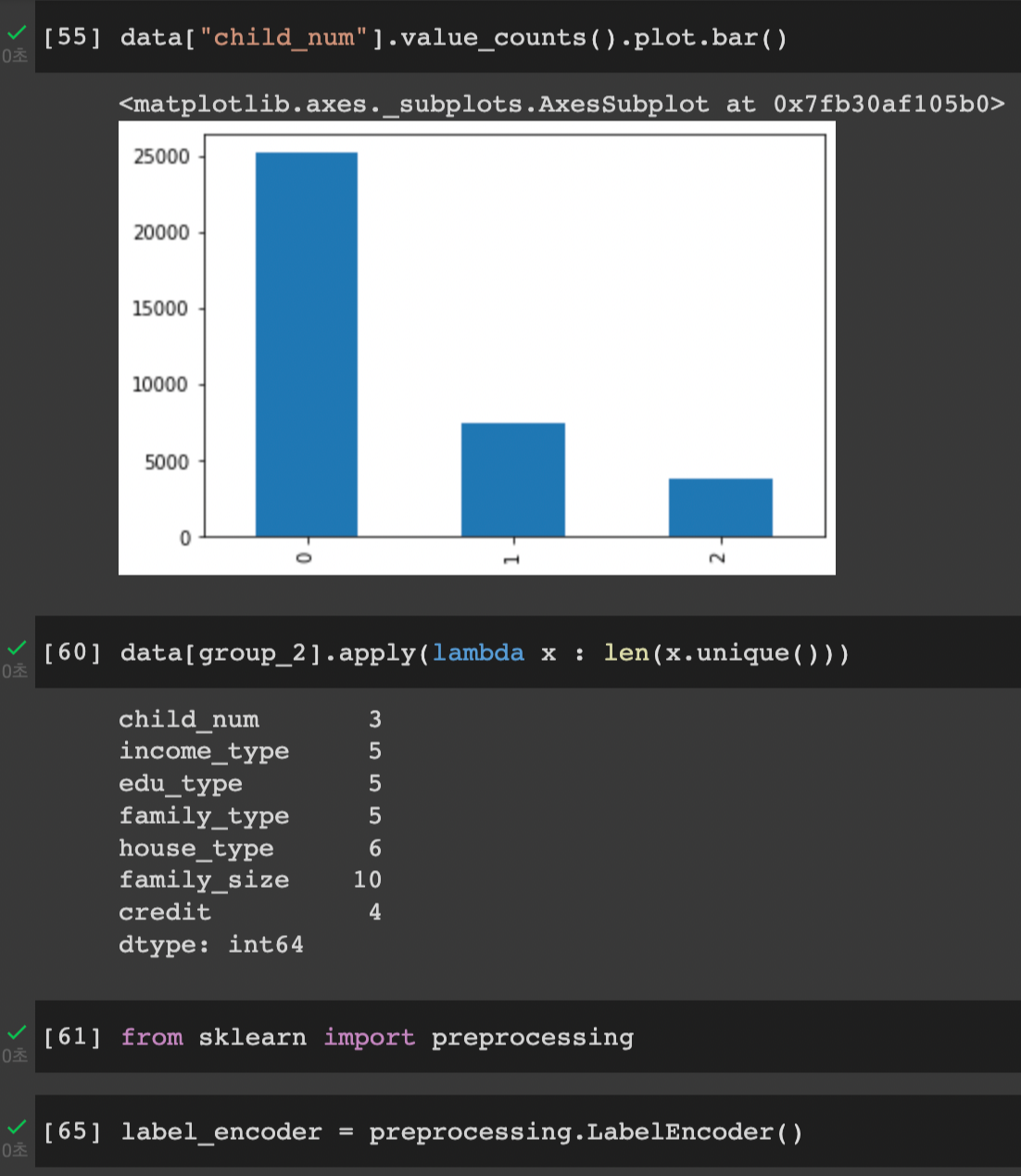
결측치(null) 값의 존재여부를 확인해주었다.

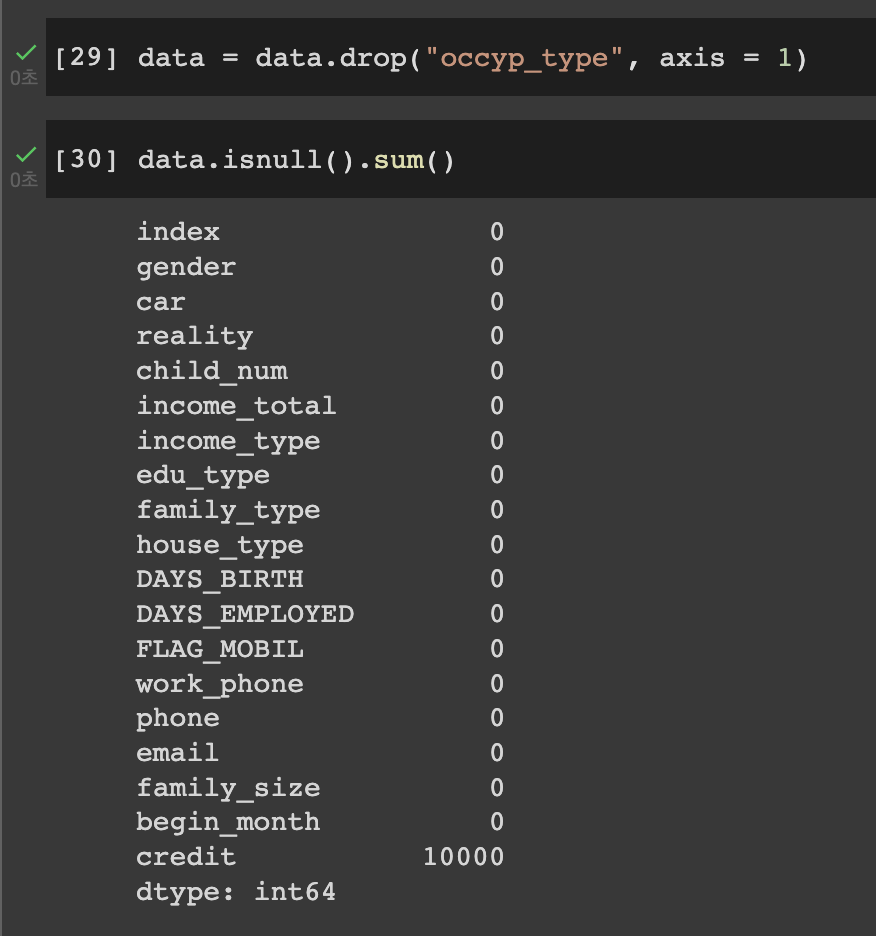
NULL 값이 된 영역을 아예 제거를 해준 모습이다.
credit엔 10000으로 적혀있지만 이것은 train, test 데이터 차이로 생긴 당연한 문제이기 때문에 무시하면 된다.
22.12.03. (토)

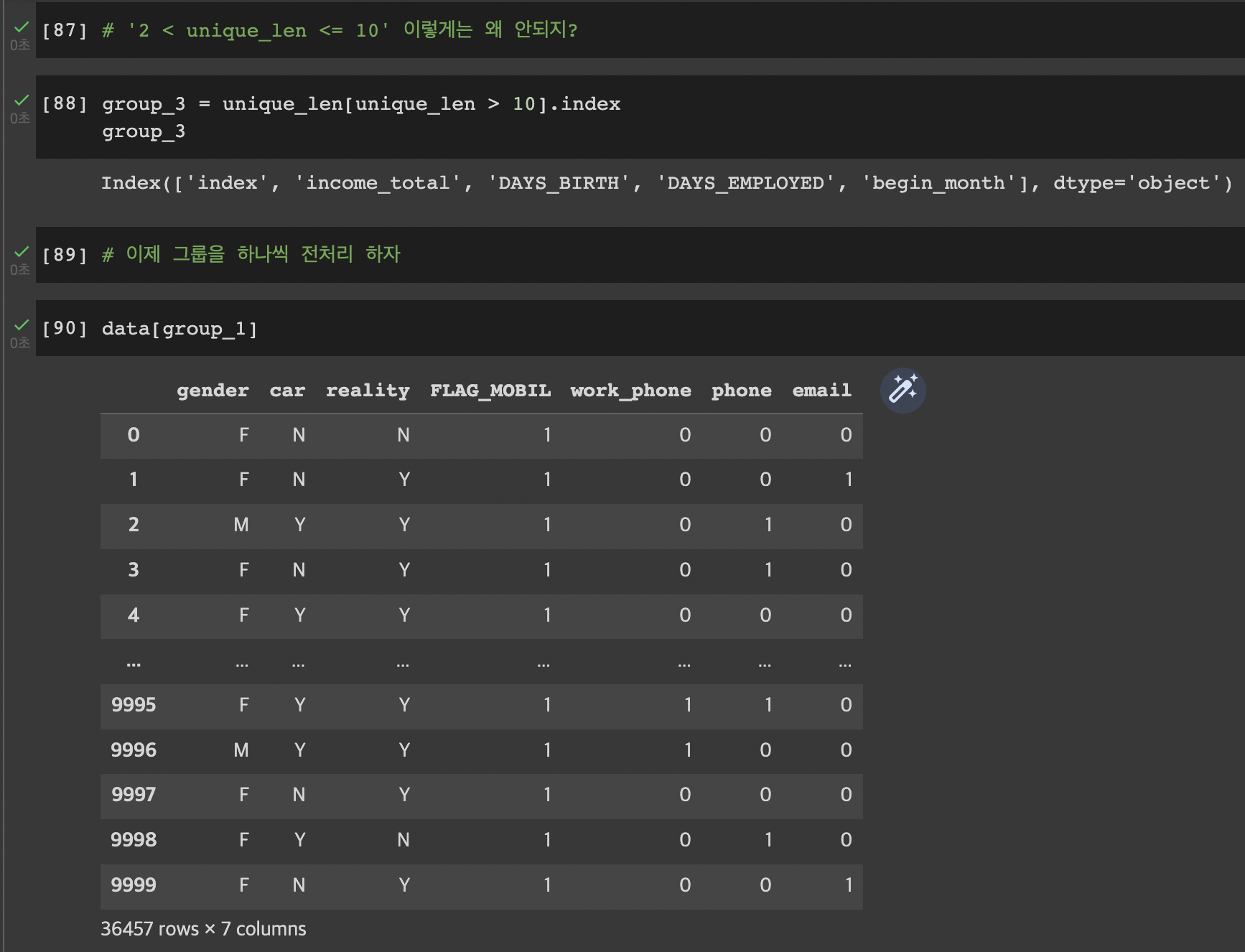
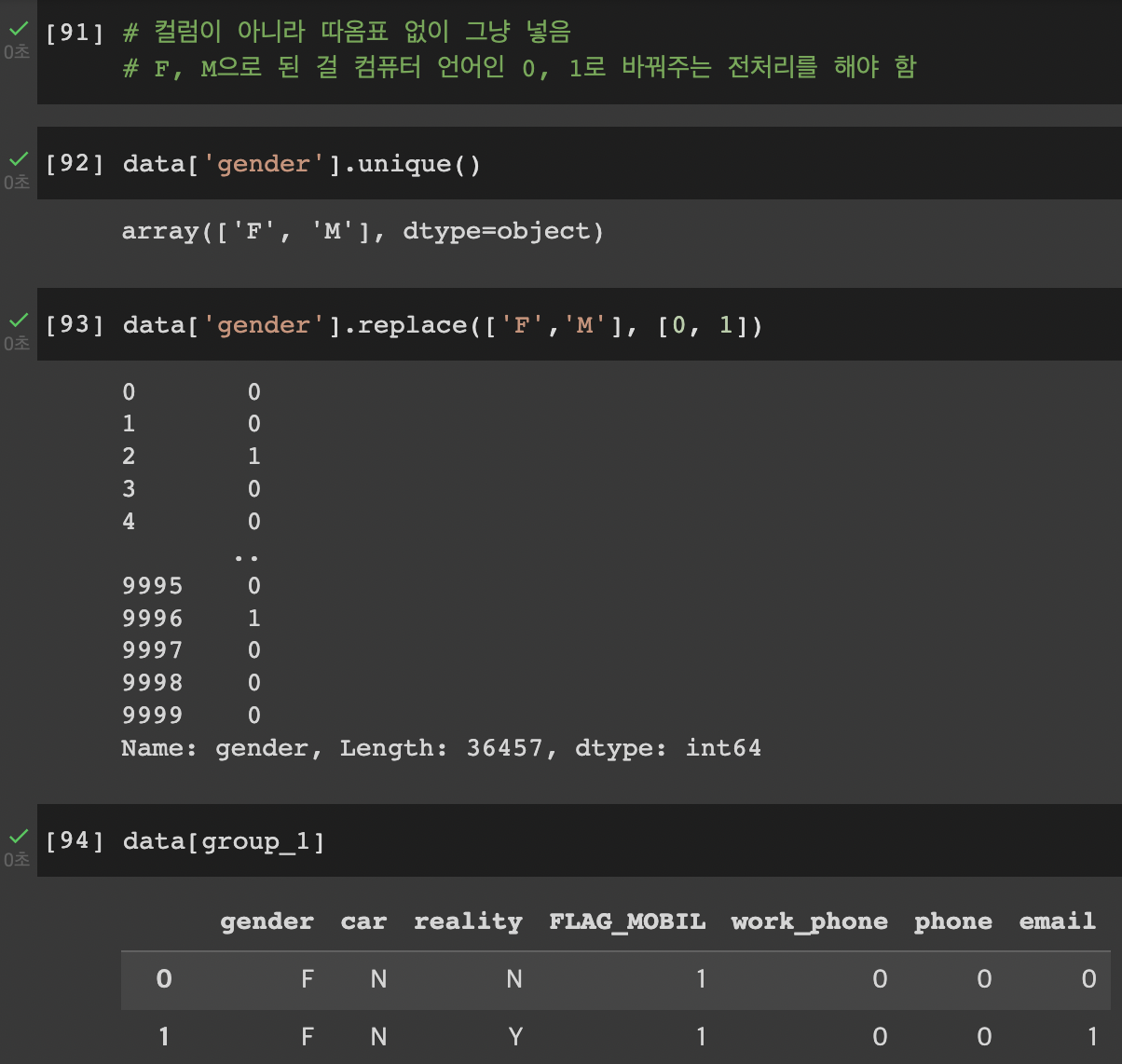
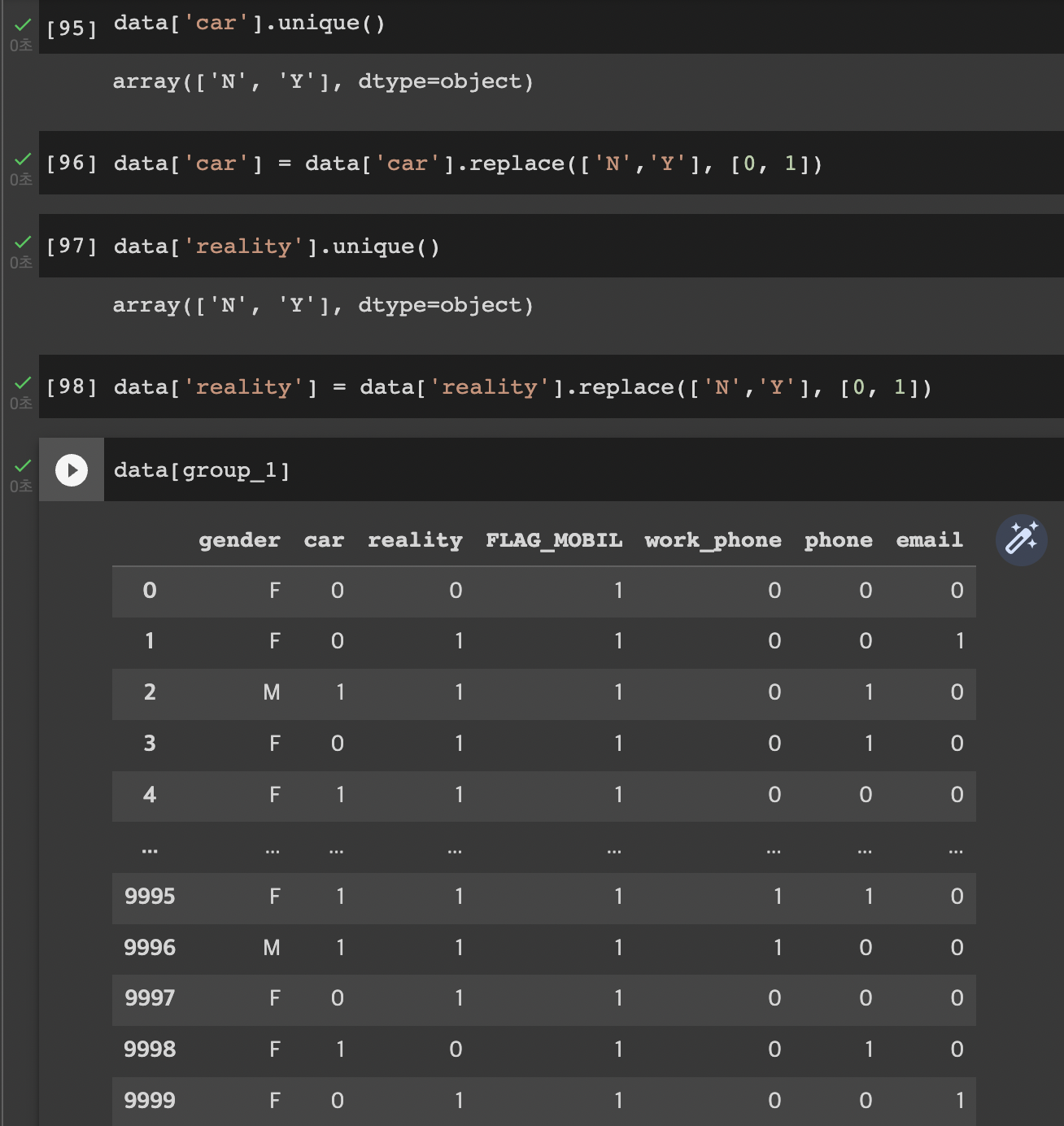
22.12.04. (일)
'IT 연구 > Python' 카테고리의 다른 글
| [Python 독학] 파이썬 IDLE 사용해보기 (0) | 2023.02.02 |
|---|
